Design Twitter
1. Introduction
Twitter is an online microblogging and social media platform where people post and interact with messages called as tweets. Registered users can post, like, and retweet tweets, but unregistered users can only read them.
Prerequisites :
System design introduction : 3 principles of distributed system, 5 step guide for System design.
System design concepts & components : Horizontal scaling, Database, Communication protocols, Caching
2. Requirement analysis
Functional requirements
- User should be able to post tweets.
- User should be able to follow other users.
- User should be able to see his timeline filled with top tweets from his followers
Non-functional requirements
- Service should be highly available – You should be always able to access twitter website, read the feed and post tweets.
- Service should be reliable – there should be no data loss. Once you post a tweet successfully it shouldn’t be lost.
- Service should have minimum latency. Consistency can take a hit for latency.
Additional requirements
- User should be able to search tweets.
- Replying to a tweet.
- Retweeting
- Trending topics
- Sending messages
3. API design
- boolean tweet(userId, tweetText, location)
- Json populateFeed(userId)
- boolean follow(followId)
4. Define data model
User : userId(PK), name, email, creationDate, lastLogin
Tweet : tweetId(PK), data, location, creationDate
Follow : userId1, userId2
Which database to use?
Column-wide database like Cassandra.
5. Back-of-the-envelope estimations
Question :
If we have 1 million tweets sent each second with average tweet size 1 KB we need to calculate how much data will be generated in next 5 years?
Answer :
- 1 Million * 1KB = 1000000 KB in 1 second = 1000MB in 1 second = 1 GB in 1 second
- 1GB * 60 * 60 * 24 in 1 day = 1 * 3600 * 24 = 4000 GB * 25 = 100,000 GB = 100 TB in 1 day
- In 1 year we have 365 * 100TB = 36500 TB = 40000 TB = 40 PB
- In 5 years we have 40 PB * 5 = 200 Petabytes.
- Considering that we should not use more that 70% of our capacity we have 200 * 100 / 70 = 2000/7 = 300 PB
- Reads are almost 50 times more than writes. So we will read 1 GB * 50 = 50 GB in 1 second.
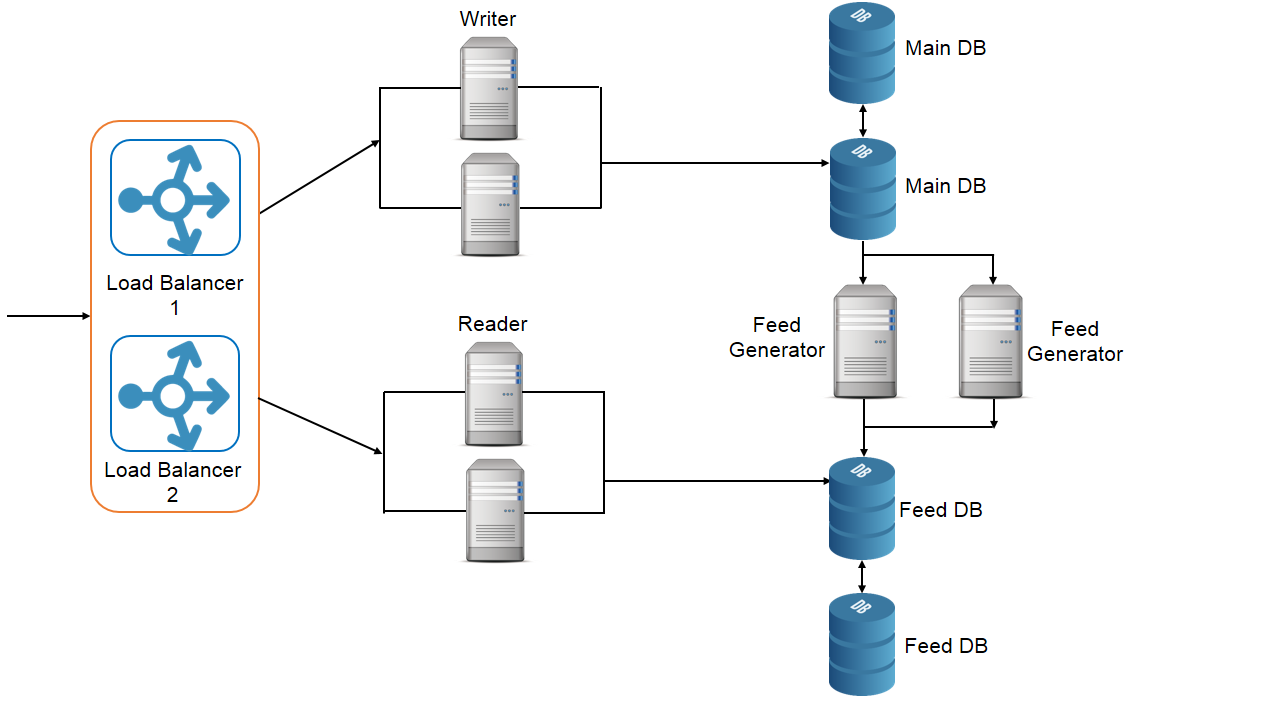
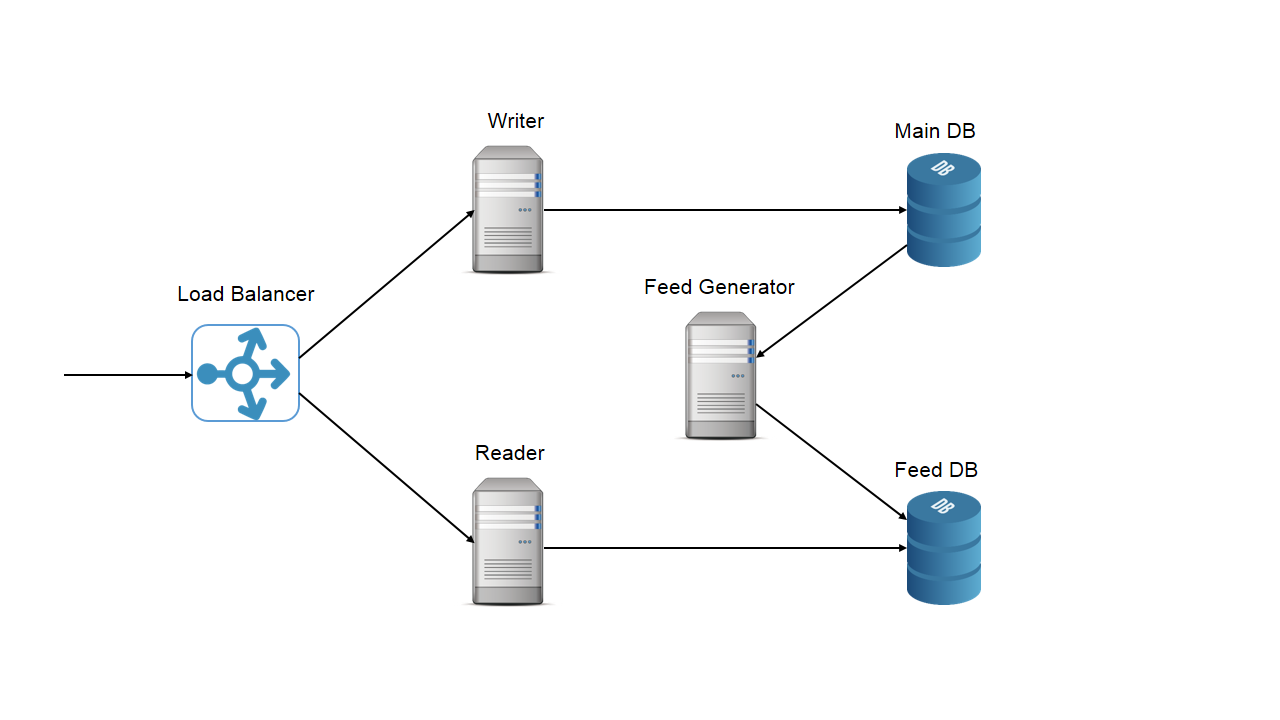
6. High level design
We can consider twitter as an extension of the reader/writer design problem.
Challenge :
Suppose a user follows 500 people out of which 200 tweet daily. What are the different ways to populate the user’s timeline.
Solution :
- Populate based on the tweet’s creation time.
- Use some recommendation system which is based on some parameters which suggest the top 20 tweets for the user.
Challenge :
Our solution works perfectly fine for normal users. But for celebrity users we have a problem. They have millions of followers.
Solution :
Pregenerate the feed of only normal followers.
Challenge :
How to refresh the feed?
Solution :
- Push model
- Pull model
Challenge :
How do we handle infinite scrolling and loading the older tweets.
Solution :
Let the system compute 20 additional tweets beforehand each time we load 20 tweets.
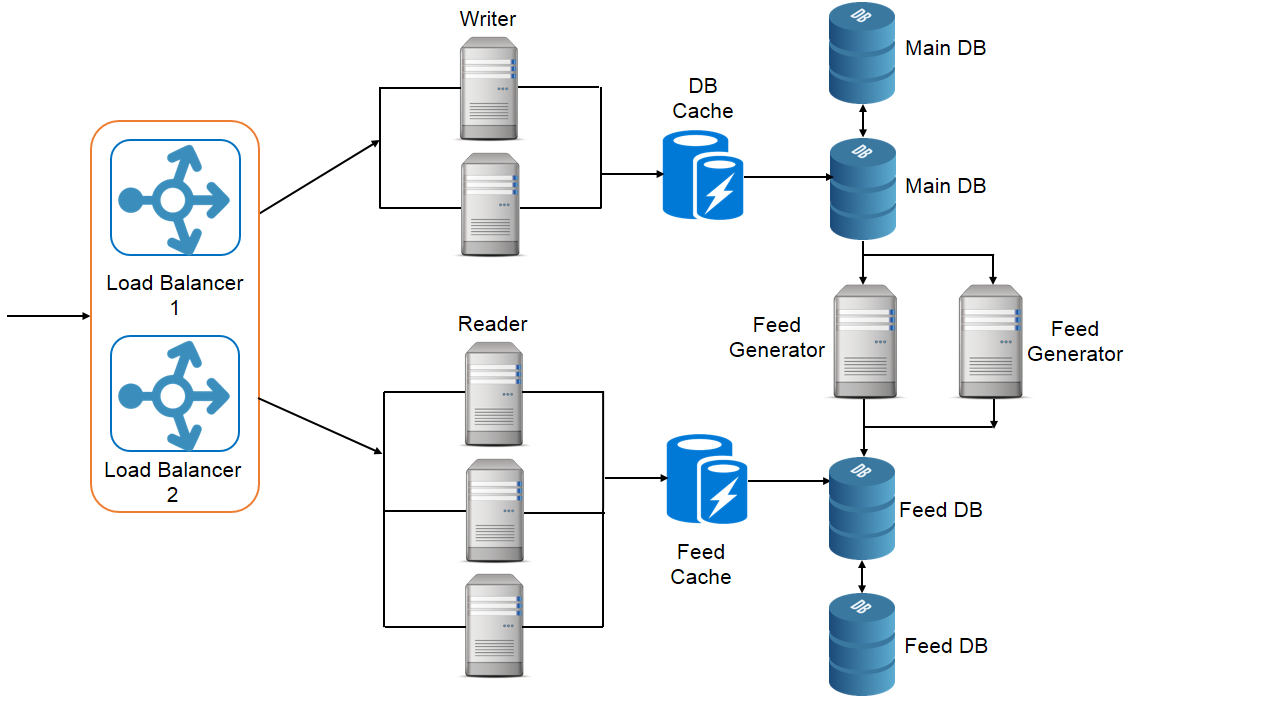
7. Scaling the design
Let us see our non-functional requirements.
- Service should be highly available – We should be always able to access twitter website, read the feed and post tweets. High availability can be achieved by no single point of failure principle.
- Service should be reliable – there should be no data loss. Once you post a tweet successfully it shouldn’t be lost. This can be achieved by saving redundant copies of data.
- Service should have minimum latency. Consistency can take a hit for latency – It is perfectly fine if we post a tweet and it takes up some time to show it in our followers feed i.e. there is eventual consistency. We can also add caching for faster reads.