Design Distributed Web Crawler
1. Introduction
Web crawler or spider or spiderbot is an internet bot which crawls the webpages mainly for the purpose of indexing. A distributed web crawler typically employs several machines to perform crawling. One of the most famous distributed web crawler is Google’s web crawler which indexes all the web pages on the internet.
Prerequisites :
System design introduction : 3 principles of distributed system, 5 step guide for System design.
System design concepts & components : Horizontal scaling, Database, Message queues, Caching
2. Requirement analysis
Functional requirements
- Crawl only HTML pages
- Crawl only HTTP pages
- Crawler should be polite
- It should accept seed urls. These are the urls to begin with.
- The crawled pages should be saved. Currently there is no need of performing any additional processing.
Non-functional requirements
- Availability – Crawler should not crash while doing its job.
- Service should have minimum latency.
3. API design
There are no APIs. We are making http requests to webpages and saving them.
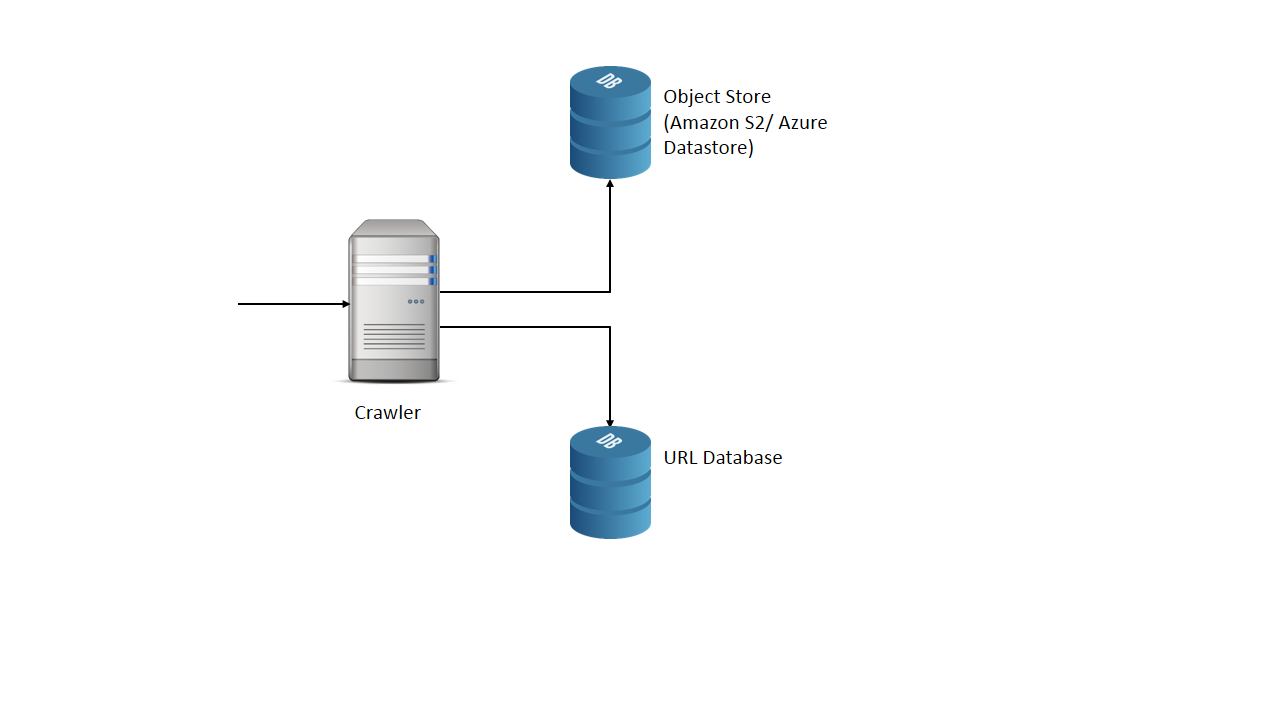
4. Define data model
URL : url(PK), IsVisited, visitedTimestamp
Which database to use?
NoSQL Key value database like DynamoDB
Where to save the web pages?
Object store like Azure blob storage or Amazon S3
5. Back-of-the-envelope estimations
We need to perform 2 estimations
- Suppose we want to crawl 1 billion pages in 10 days. We need to find how many pages should be crawled in 1 second so that we can decide on the number of servers needed?
- We need to save 1 billion pages having approx. 1MB size each. So how much capacity should be reserved to save this data?
Solution 1 :
- 1 billion pages in 10 days
- 100M in 1 day.
- 100M / 24 ≈ 100M / 25 = 4Million per hour.
- 4M / (60 * 60) = 4000000 / 3600 = 40000 / 36 ≈ 40000 / 40 = 1000 pages per second.
- Considering each server can handle 100 pages per second we will need 10 servers.
- Since we want our servers to run at 70% capacity we will need 13 servers.
Solution 2 :
- 1 Billion * 1MB = 1000 Million * 1MB = 1 Million GB = 1 petabyte.
- Since we do not want to exceed 70% capacity we will need 1.3 petabyte storage.
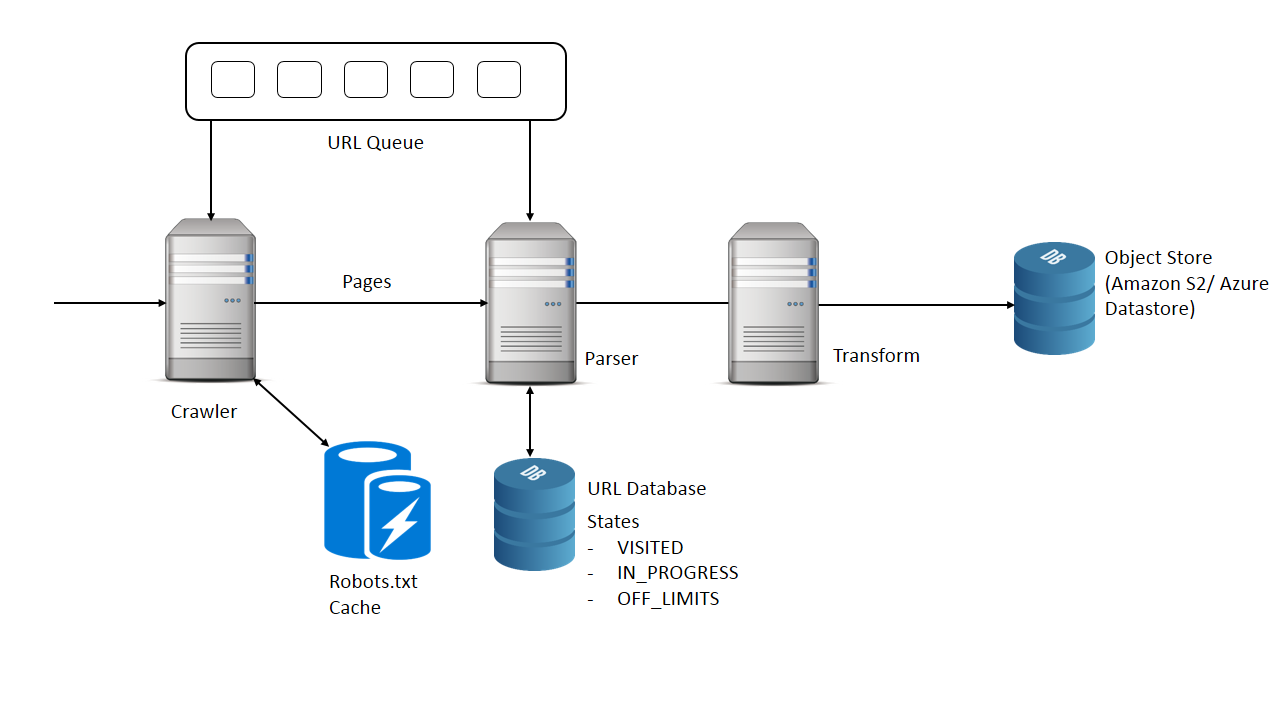
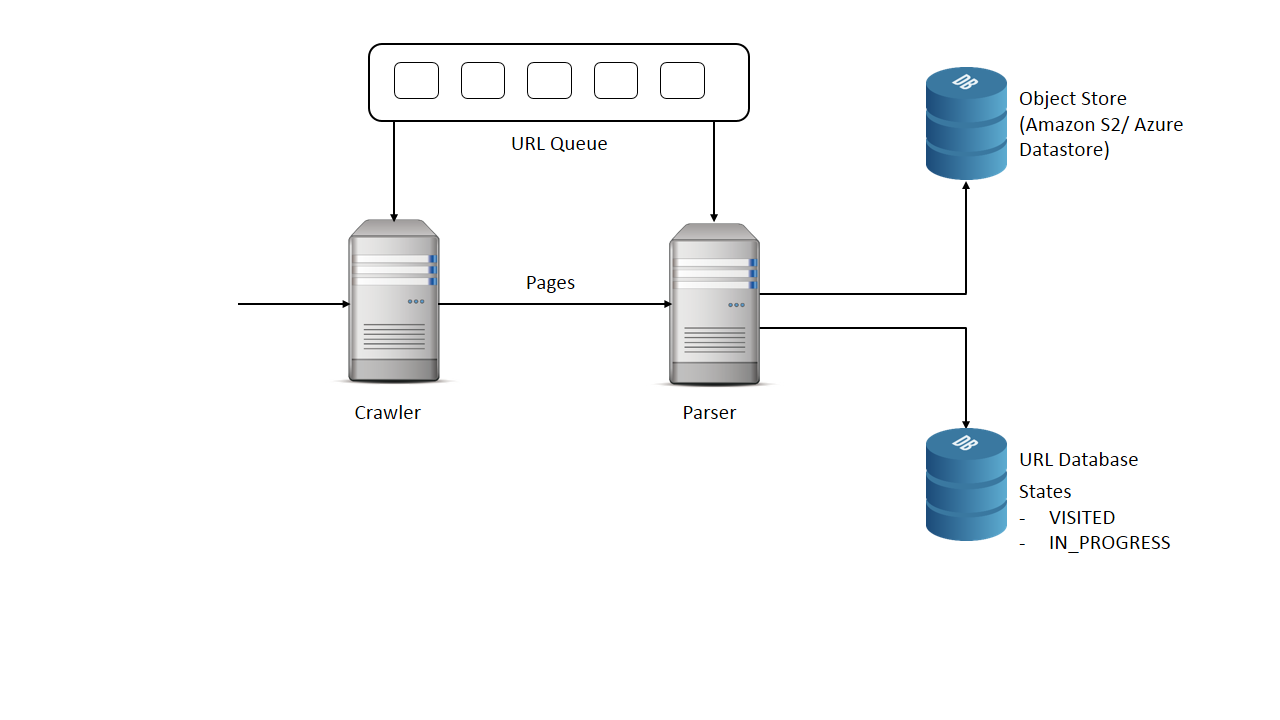
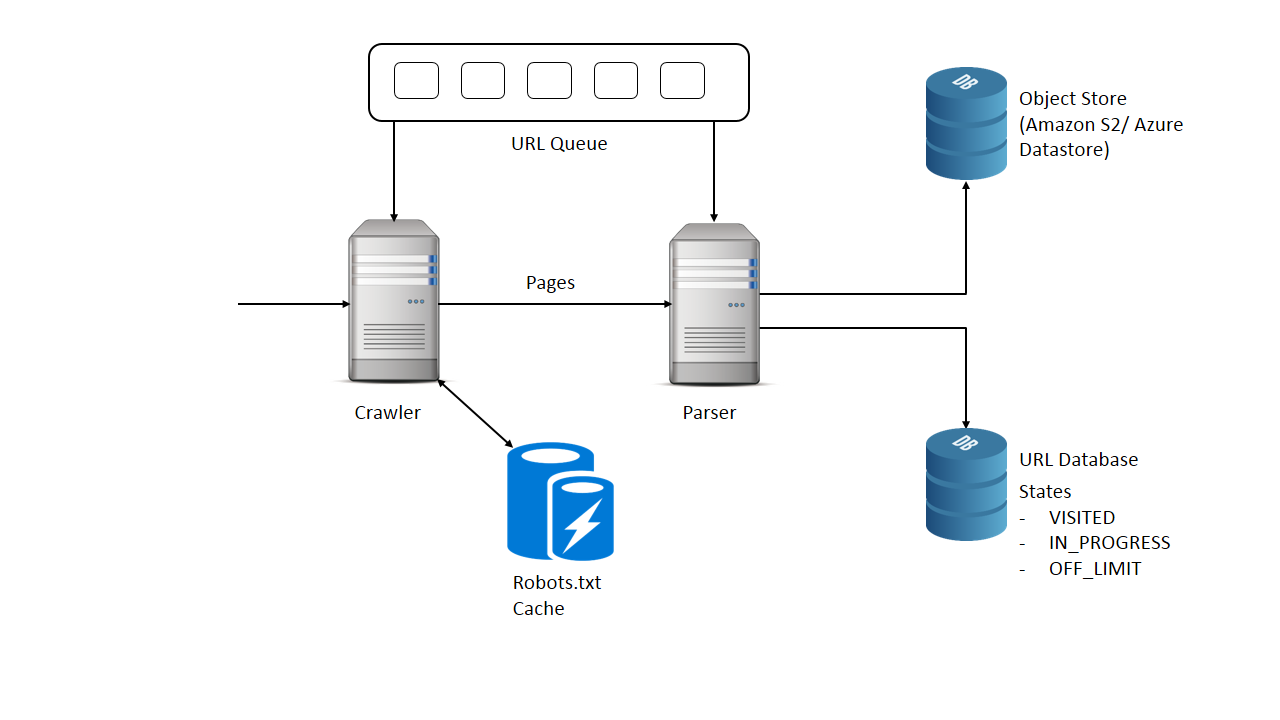
6. High level design
Diagram shows a simple web crawler.
Which algorithm to use for scanning the pages?
- DFS – Depth first search algorithm : Here a web page is scanned and all the URLs present in it are pushed into a stack.
- BFS – Breadth first technique : Here a web page is scanned and all the URLs present in added into a queue.
Same URL might be added twice in queue so those pages will be downloaded twice. How do we prevent it?
- One way to solve it is, let the crawler before accessing every page check if it is visited.
- Maintain the states of the URL if it is VISITED or IN_PROGRESS which means it is added to the queue.
Single responsibility principle
Our crawler is doing mainly 2 things.
- Crawling the internet
- Parsing the webpages.
How to make the crawler polite?
- Read and cache the robots.txt file.
- Employ some sort of rate limiter which will limit the number of requests per some time period our crawler does to a website.
7. Scale the design
Let us revisit our non-functional requirements
- Availability – Crawler should not crash while doing its job. It can be achieved using the no single point of failure principle.
- Service should have minimum latency. This is achieved using the no bottleneck principle. We need to have partitions to the queue to make it scalable.
8. Additional things
- Extensibility
- Cluster of crawlers
- Crawler traps