System Design Concepts & Components
This section will deal with some of important system design concepts and components used in system design. In this section, you will learn important concepts of system design such as scaling, load balancing, caching and many others. You will understand the importance of each of these concepts while designing a system, also you will get to know different components used in system design such as web servers, app servers, databases etc.
1. Scaling
Large enterprises have large amounts of data. With increasing amounts of data the system should also grow to manage it effectively. This process of growing or shrinking of the system to handle data is called scaling.
Scaling of any system can be achieved by two ways.
- Vertical Scaling : Vertical scaling means upgrading the hardware/software of the existing system. Adding more power to it more RAM, CPU’s and HDD. But with vertical scaling there is always a limit a max beyond which it cannot go higher.
- Horizontal Scaling : Horizontal scaling means adding multiple additional systems to improve the performance. Typically we might use several low end commodity hardware to save the cost.
Horizontal Scaling
- Might need load balancers
- Resilient to system failures
- Data inconsistency
- Scales well
Vertical Scaling
- Load balancer is not necessary
- Single point of failures
- Data consistency
- Has hardware limit for scaling
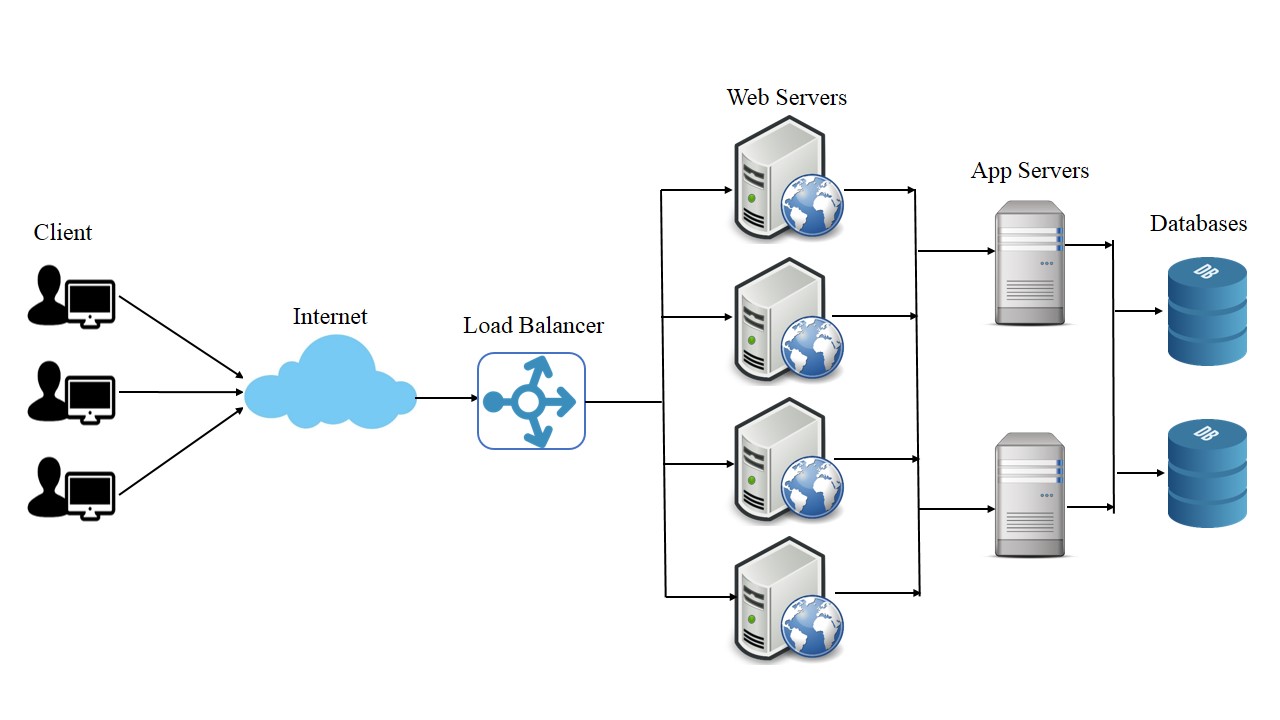
2. Load Balancing
Load balancer helps distribute incoming traffic across servers or databases. There are 2 types of load balancers hardware and software. Hardware load balancers are generally expensive but very effective.
You can use multiple load balancers to avoid single point of failure. They can be in active-active mode or active-passive mode.
Following algorithms are largely used for load balancing purpose.
- Round Robin
- Least Loaded
- Session Based
- Hashing


3. Caching
Caching is a concept where data is stored in fast memory for quick access. The cache is generally a temporary storage like RAM since it is faster than reading the data from HDD or a database.
There is a famous 80:20 rule which states that 20% of the data is accessed almost 80% of the time. So generally we try to keep that 20% data in the cache.
Cache Invalidation
- Write-through cache: Data is written in cache and database at the same time.
- Write-around cache: Data is written in database only. Cache is marked as invalid. It is written later in cache.
- Write-back cache: Data is written in cache only. It is written later in db.
Cache Eviction
- Least Recently Used (LRU)
- Most Recently Used (MRU)
- First In First Out (FIFO)
- Last In First Out (LIFO)
- Least Frequently Used (LFU)
- Random Replacement (RR)


Distributed caching
4. Consistent Hashing
Consistent hashing is one of the techniques used to bake in scalability into the storage architecture of your system.
In a distributed system, consistent hashing helps in solving following scenarios:
- To Provide elastic scaling (a term used to describe synamic adding/removing of servers based on usage load) for cache servers.
- Scale out a set of storage nodes like NoSQL databases.







5. Storage
Object Store
Object store or object-based storage is a storage architecture which manages data as objects unlike your regular hard disks which manages it as files in a file hierarchy system.
RAID
Redundant array of independent disks (RAID) is a way of storing the same data on multiple hard disks or solid state drives to protect it in case of failures. There is a RAID controller which handles all the operations and is responsible for improving performance while writing and protecting the data on multiple devices.
RAID Levels
RAID levels are nothing but different configurations. There are 6 standard levels of RAID from RAID 0 to RAID 5, then there are several combined RAID levels like RAID 10 and many non standard RAID levels which companies have developed for their own use. For the purpose of this section we will go through RAID 0 to RAID 5 and a combination RAID 10. These are good to know topics for design interview. You can ignore the other RAID levels safely.
- RAID 0 – Striping
- RAID 1 – Mirroring
- RAID 2 – Bit-level striping with dedicated Hamming-code parity
- RAID 3 – Byte-level striping with a single parity disk
- RAID 4 – Block-level striping with a single parity disk
- RAID 5 – Striping with distributed parity
- RAID 6 – Striping with double parity
- RAID 10 – Combining striping and mirroring








6. Database Concepts
A database is a collection of information that is organized so that it can be easily accessed, managed and updated. In this section you will get to know about various database concepts like CAP theorem, ACID properties, Consistency patterns and Sharding.
3 guarantees of a distributed system
- Consistency — A guarantee that every node in a distributed cluster returns the same, most recent, successful write.
- Availability — Every non-failing node returns a response for all read and write requests in a reasonable amount of time
- Partition Tolerant — The system continues to function in spite of network partitions.

CAP theorem states that it is impossible for a distributed software system to simultaneously provide more than two out of three of the following guarantees (CAP): Consistency, Availability, and Partition tolerance. While designing a distributed system we can pick up only 2 of the 3 options.
CAP theorem is one of the parameters used when choosing the database for your system.

ACID Properties
- Atomicity
- Consistency
- Isolation
- Durability
We know that a transaction is a single logical unit of work consisting of one or more instructions which accesses and possibly modifies the contents of a database. To maintain integrity of the database each transaction should be ACID compliant.
Database Replication
Database replication is the process of copying data from one database to one or more databases.
Consistency Patterns
Distributed databases that rely on replication for high availability, low latency or both, we need to make a trade-off between the read consistency vs throughput. There are 2 general consistency levels supported by most distributed databases.
- Strong consistency
- Eventual consistency
Replication architectures
- Single-leader architecture
- Multi-leader architecture
- No-leader architecture
Sharding
Sharding a database is horizontal partitioning a database.
Factors to be considered while sharding
- Data size
- Performance
- Latency
- Cost
Ways to shard the data
- Divide based on some column value
- Divide based on some algorithm or hash function
- Consistent hashing

NoSQL and it’s types
A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
There are 4 main Nosql types
1. Key-value store
As the name suggests the data is saved into a key value pair. Some of the most famous in this category are Redis, Amazon’s Dynamo and Voldemort.
2. Column oriented database
Traditional databases are row oriented. All the columns of a row are stored together. A column-oriented stores data tables by column rather than by row. Some of the famous column oriented databases are Cassandra and HBase.
3. Document-based
Here we save the data into a form of documents. These documents should have some schema either fixed or unfixed and it can be expressed in json format. Some examples are MongoDB and CouchDB.
4. Graph-based
When the data is highly interconnected and it can be depicted as nodes and edges we can use graph based databases. The nodes can be entities and the edges can be relationships. An example of a graph based database is Neo4j.
7. Web Servers
A web server is a dedicated server whose functionality is to serve web requests only. It serves HTML documents, images, CSS stylesheets, and JavaScript files.
8. Application servers
An application server or app server is used to host applications. These applications generally are the business logic of the system. An app server provides the environment both software and hardware to run them.
9. Architectural patterns
1. Monolithic
In monolithic pattern the entire business logic is composed in one single component.
2. Layered
In the layered pattern the components are grouped into logical layers. Each request will go through the layers performing some specific tasks.
3. SOA – Service oriented architecture
SOA defines a way of making components reusable via service interfaces. In this pattern each component is actually a service performing some specific functionality.
4. Microservices architecture
Microservices architecture is a style which allows building an application as a collection of small independent services. Each independent service is called a microservice.
Some features of microservice are
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities i.e. Single responsibility principle
- Owned by a small team
Most microservices based systems have some common components.
- API gateway
- Service discovery
- Service management



10. Message queues
Message queues are typically used to provide asynchronous communication between components in a system. We can divide the message queue into parts where each part serves a specific purpose. Messages belonging to some particular category can go into its respective part. Some examples of the products which provide message queues are Kafka, RabbitMQ and Azure service bus.

11. Communication models and Protocols
Communication models
- Push
Here sender actively sends the messages to receiver whenever a message is available. - Pull
Here the receiver asks sender if a message is present. If it is present it pulls the message.
Communication Protocols
- Http
- Long polling
- Websockets



12. Security
Basic concepts
- Authentication
- Authorization
- Encryption
- Integrity
- Symmetric encryption
- Asymmetric encryption
- Certificate
- Certification Authority(CA)
- Cross-Site Scripting(XSS)
- Denial of Service(DoS)
- Distributed Denial of Service(DDoS)
13. Content delivery network (CDN)
A content delivery network (CDN) refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content.
14. Back-of-the-envelop calculations
Back-of-the-envelop estimations means the quick calculations you do on back of the envelop or on paper.
Question:
Estimate how many servers we need to serve read requests considering each server is capable of handling 7 requests per second. We have to serve a total traffic of 46 Million per day.
Answer:
- 7 requests per second
- 7*60 = 420 requests per minute
- 420*60 requests per hour = 400 * 60 = 24000 per hour = 24K per hour
- 24K * 24 requests per day ≈ 30K*20 = 600K requests per day per server
- We want to handle 46 Million requests per day which means 46M/600K = approx 45M/500K = 45M/0.5M = 45*2 = 90 servers.
Question:
Given 46 servers and 46 Million requests per day how much data does each server process per second?
Answer:
- So 1 server will have 1 Million requests per day.
- 1 server will have 1 Million/24 requests per hour = 1000000/24 = 1000K/24 ≈ 1000K/25 = 40K requests per hour.
- 1 server will have 40K/60 requests per minute = 4K/6 = 4000/6 = 3600/6 = 600 requests per minute.
- 1 server will have 600/60 requests per second = 60/6 = 10 requests per second.
Cheat sheet
- 1 Bit
- 1 Byte = 8 bits
- 1 Kilobyte (KB) = 1024 Bytes ≈ 1000 Bytes
- 1 Megabyte (MB) = 1024 KB ≈ 1000 KB
- 1 Gigabyte (GB) = 1024 MB ≈ 1000 MB
- 1 Terabyte (TB) = 1024 GB ≈ 1000 GB
- 1 Petabyte (PB) = 1024 TB ≈ 1000 TB
- 1 Exabyte (EB) = 1024 PB ≈ 1000 PB
Kb vs KB: Serial communications and read/write devices use Kb (Kilo-bits) for data transfer ratings whereas storage devices use KB (Kilo-Byte) to rate their capacity.
1 KB(kilobyte) = 1024 bytes = 1024 * 8 bits = 8196 bits
1 Kb(kilobits) = 1024 bits = 1024/8 bytes = 128 bytes.